3 The data model¶
3.1 Approach¶
In the three schema approach a conceptual data model is proposed as an effective way to integrate between different databases and organisations. In the conceptual model the data entities are defined in the way that the end-users think and talk about concepts in the real world. It is therefore assumed that multiple organisations can easily develop a mapping from their own internal data structures onto such conceptual model because of the internal logic of the end-user community. The conceptual model can therefore function as a neutral and organisation independent interface for the data from 1 database to another database. If all organisations would develop such a mapping (or adapt their own internal data structures), effortless and automated data exchange and data integration can take place. The reference framework for first mile farm data aims to put the foundation for such a neutral model.
In ‘first mile’ projects many different aspects of farms are being collected. Examples are the agricultural and economic performance of a farm, farming activities performed at a farm, social and environmental conditions, compliance to standard measures etc. It is beyond the scope of this document to address all of these aspects in detail, including the recommended field data collection methodologies and associated data formats. This document presents a generic structure by representing the core components of a farm as data entities. It will only discuss data attributes that are essential for the internal structure and which are needed to be able understand and combine the data, such as farmers ID or the shape of the fields or are commonly collected such as the address or expected yield. It will also present the logic how the model can be expanded with additional data attributes or data entities providing the option to customise the model and to provide the opportunity to expand the generic model into a more all comprehensive model at a later stage.
3.1.1 The conceptual model¶
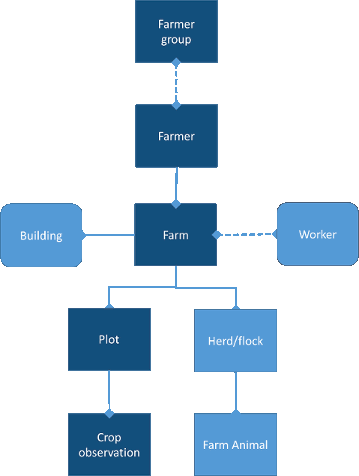
To define the conceptual data model, the concept of a farm is taken as the starting point. A farm in this reference framework is defined as a collection assets managed as 1 entity with the primarily objective to raise living organisms for food or raw materials. At the farm crops are cultivated on one or more plots of land and farm animals are being kept. The farm is run by a farmer, often supported by farm workers. Different buildings may be present at the farm to support the work. The farm may consist of multiple plots, herds or buildings. Workers are not bound to 1 farm but may work at different farms. A farmer may manage several farms. A farmer may be member of one or more farmers groups. A farmer group can be a cooperative or a group of farmers loosely organised around a government or corporate program.
Many organisations are making observations in a plot during their field work. The data entity ‘observation’ is introduced to map this observation data.
The conceptual model is flexible to include a number of different farmer and farm types depending on the ownership of the farm and ownership of farm assets. Traditionally one may think of the farmer being the owner of both the farm and the farm assets, however this is not always the case. In many cases a farmer will hire or lease part of the production assets. ‘Sharecroppers’ or ‘Tenant farmers’ make use of agricultural assets which they do not own and have to pay a percentage of the profit, part of the produce or both. In ‘systems with communal land rights’ members of the community are getting fields assigned to use for farming, but do not own the land. Land use rights may change through time. The land of a farm is therefore a not static asset but may change through time.
In some cases the farmer is more like ‘the manager’ and not ‘the owner’ of the farm benefitting directly from the produce of the farm. When the rights are shared with a group of individuals, the farm can be called a ‘Communal farm’. When ownership rights are with a company the farm can be called a ‘Corporate farm’. By managing the concept of ownership well for the different data entities all of these different type of farms and farmers can be included in the model, even while ownership changes over time.
The logic of the model is to map the first mile data elements collected in the field work at the right level data entity. Eg.:
- The certified stock of a cooperative should be a data element of the data entity group
- The total certified produce of a farm should be a data element of the data entity farm
- The expected harvest of a field should be a data element of the data entity group
The dark blue elements in the figure above indicated in the model will be detailed out more below. The lighter blue elements to visualize the logic in the model and to indicate possible extensions in the future or customization options.
3.2 Overview of model JSON model¶
The complete data structure is visualised in the table below:
- All required data attributes are indicated in bold,
- By clicking on the blue table title -> all data attributes become visible,
- By clicking on the data entity buttons -> all data ttributes become visible of that data entity and,
- By clicking on the {} symbols -> the JSON becomes visable
In JSON schema language the data entities making up the conceptual model (Group, Farmer, Farm, Plot, Observation) as described in the conceptual model are stored as arrays of JSON objects.
Each time a data entity is recorded a new JSON object is created and added to the array. The recording of the same data entity at another point in time needs to be added as a new record to allow for continuous monitoring and to allow the composition of farms and ownership to change overtime. The recording of the data entities therefore are timestamped, this takes place in the GlobalRecordID object (see below)In the reference framework a system of 3 identifiers is proposed to uniquely identify objects and model the relationships between these objects. These Identifiers are called: 1 the GlobalRecordID, 2 the GeoID and 3 the InternalID. The system allows the exchange and merging of data from different organisations if both datasets are following the first mile data structure.
- The GlobalRecordID is a globally unique identifier for First Mile Farm data record.
- The InternalID provides a means to internally structure the data set, uniquely identifying the objects in the database and the relations between them.
- The GeoID provides an imperfect means to uniquely identify the object in the field and to clean the dataset when it is combined with datasets from other sources.
This mechanism will be explained in more detail in section on ‘Uniquely Identifying Data Elements‘.
It is not required to use all data entities (Farmer group, Farmer, Farm, Plot, Plot Observation) in a databases while using the data structure. Some organisations only collect plot level data, so no details are needed/available on which farmer manages the plot or to whom the plot belongs. The arrays for group, farmer, and farm can be left empty.
However because all data elements are mapped on the same data entities, datasets with different levels of ‘completeness’can still be combined for analysis. E.g. if an organisation who collects plot data, farm data and farmer data uses the same structure to organise its plot data as an organisation who only collects plot data, all plot level data entries can be combined and analysed collectively in a meta analysis.
As a result, to maintain compatibility for different global data sources, with different combinations of data entities (Farmer group, Farmer, Farm, Plot, Plot Observation), it is essential that all data attributes are mapped at the right data entity level. For example it does not fit the logic of the reference framework to add an attribute ‘farm size’ to the data entity ‘farmer’, even if that farmer owns or manages that farm. The farm and it’s size are inextricable, even if this is the only attribute recorded about farms in the data set. As a result the farm size of a farmer’s farm can only be found by first finding the farm instance of the farmer’s farm using internals keys and next the size of that farm instance.
3.2.1 Extensions¶
The reference framework is designed in such a way that new data attributes or even new data entities for different purposes can be added to the model easily. This is illustrated under the heading extensions, for Cocoa action program and MARS Adoption Observations. The data formats are available together with the official protocols on how to collect the data elements in the field.
By adding more and more extensions to the reference framework, a repositry emerges of ‘proven’ data formats and data collection protocols. Organsations can benefit from this repositry harvesting the formats and data collection protocols they need for their own data management. Having different data formats and datacollection methodologies in one repository will also facilitate further standardization and interoperability discussions. To add to the reference framework please contact andre.jellema@data-impact.com.
In the following sections the core data entities of the generic data structure for farm data collection, storag and exchange will be further elaborated under the Chapter ‘Extentions”.
3.3 Schema details in JSON¶
3.3.1 Farmer group¶
Definition Loosely defined group of farmers. Farmers can be member of a cooperative or union, organized by a company as contract farmers or as part of a support program, etc.
Data attributes Many attributes can be assigned to a group, also depending on the nature of the group. Some examples of common attributes are provided, like the area of operation, the valid certifications from standard organisations, total amount of certified produce in stock. Details will not be specified in depth in this version of the reference framework for first mile farm data collection, storage and exchange. The entity is presented here to demonstrate a coherent framework which is ready to be expanded or customized depending on the requirements.
As explained in the section ‘Uniquely identifying data elements‘ {GroupRecordGlobalID, GroupInternalID, GroupGeoID} provides the means to: 1 globally uniquely identify all the records of farmer groups, 2 to provide each farmer group with a unique interal ID which allows to link other data entities to this farmer group and; 3 to have a clue to uniquely identify this farmer group in the field or to clean the dataset when combined with datasets from other sources.
Datastructure The data structure is visualised in the table below. All required data attributes are indicated in bold.
- By clicking on the blue table title -> all data attributes become visible,
- By clicking on the data entity buttons -> all data ttributes become visible of that data entity and,
- By clicking on the {} symbols -> the JSON becomes visible
3.3.2 The farmer¶
Definition The farmer is the person that manages one or more farms, possibly helped by farm workers. The farmer takes the major management decisions even when the decision is to do contract farming where the farm practice is often prescribed in detail by an external actor. In this model the farmer is not necessarily the owner of the farm. A farmer can manage someone else’s farm. Nor does he or she need to be the owner of the assets composing the farm, e.g a sharecropper is seen as a farmer in this model. For a more detailed explanation on how ownership plays a role in modelling different farm types, see also the conceptual model in ‘the approach‘ section.
Data attributes groupInternalIDs is an array of database specific identification numbers linking a farmer to 0, 1 or more groups.
As explained in the section ‘Uniquely identifying data elements‘ {GroupRecordGlobalID, GroupInternalID, GroupGeoID} provides the means to: 1 globally uniquely identify all the records of farmer, 2 to provide each farmer with a unique interal ID which allows to link other data entities to this farmer and; 3 to have a clue to uniquely identify this farmer in the field or to clean the dataset when combined with datasets from other sources.
Datastructure Required data attributes are indicated by grey shaded fields in the table below.
- By clicking on the blue table title -> all data attributes become visible,
- By clicking on the data entity buttons -> all data ttributes become visible of that data entity and,
- By clicking on the {} symbols -> the JSON becomes visible.
3.3.3 The farm¶
Definition A farm is described as a collection of assets managed as 1 entity with the primarily objective to raise living organisms for food or raw materials. A farm often consists of fields, buildings and livestock and is run by a farm manager and the farm owner has the rights on the produce. The farm manager and the farm owner are often united in 1 person: the farmer. A farm manager is often supported by farm workers to carry out the activities.
Data attributes In the data model the farm is modelled as a placeholder for foreign keys uniting all relevant data entities based on their keys together as 1 farm, including the farmer, the farm owner, the plots of the farm, the herds and the workers etc.
Additional data entities describing, the farm as a whole can be added to this data entity, like the farm boundary, farm area, or aggregated numbers like total amount of produce. Plot specific attributes should be added to the plot like the produce from a specific plot or a plot boundary.
As explained in section ‘Uniquely identifying data elements‘ {GroupRecordGlobalID, GroupInternalID, GroupGeoID} provides the means to: 1 globally uniquely identify all the records of farm, 2 to provide each farm with a unique interal ID which allows to link other data entities to this farmer group and; 3 to have a clue to uniquely identify this farm in the field or to clean the dataset when combined with datasets from other sources.
Datastructure Required data attributes are indicated by grey shaded fields in the table below.
- By clicking on the blue table title -> all data attributes become visible,
- By clicking on the data entity buttons -> all data ttributes become visible of that data entity and,
- By clicking on the {} symbols -> the JSON becomes visible
3.3.4 The plot¶
Definition A plot is an area of land, enclosed or otherwise, used for agricultural purposes such as cultivating crops or for livestock.
Data attributes The data entity plot describes the main and general characteristics of a plot: including location and geometry, but also agronomically. Examples are:
- seed variety (name/vendor/date/quantity in kg/ha)
- yields (kg/ha)
- pesticide use (product/trade name/vendor/date/ quantity in kg/ha)
- fertilizer use (product/trade name/vendor/date/quantity in kg/ha) and application method
- measured or calculated water use (date/quantity in kg of harvested paddy/litre water input)
- timing of the different farm activities
As explained in section ‘Uniquely identifying data elements‘ {GroupRecordGlobalID, GroupInternalID, GroupGeoID} provides the means to: 1 globally uniquely identify all the records of plots, 2 to provide each plot with a unique interal ID which allows to link other data entities to this plot and; 3 to have a clue to uniquely identify this plot in the field or to clean the dataset when combined with datasets from other sources.
The model can be expanded by creating rotation specific, crop specific data entities or data entities describing the agronomic conditions like soil type.
Additional standardization resources
Datastructure Required data attributes are indicated by grey shaded fields in the table below.
- By clicking on the blue table title -> all data attributes become visible,
- By clicking on the data entity buttons -> all data ttributes become visible of that data entity and,
- By clicking on the {} symbols -> the JSON becomes visible
3.3.5 The observation¶
Definition Data obtained from an assessment in a plot, generally done at a specific location, in a transect or in an area. This data entity is not meant to describe the plot as a whole. Based on observations estimates are made for the characteristics of the plot as a whole. The observations are records of the observation data entity, where as the estimation for the plot as a whole based on the observations should be added as a data attribute of the plot data entity. For example in a grass plot the biomass is measured at 3 points. This can be added to the data set as 3 observation records, the average biomass calculated for the plot can be added to the plot data entity.
Data attributes Typical observations are:
- crop height,
- number of branches,
- height of Jorquette,
- percentage of trees show old wilted,
- number of dead or mummified pods,
- number of dead branches,
- number of damaged or diseased pods,
- number of epiphytes
- number of ant nests/tunnels nests,
- etc.
As explained in section the ‘Uniquely identifying data elements‘ {GroupRecordGlobalID, GroupInternalID, GroupGeoID} provides the means to: 1 globally uniquely identify all the records of observations, 2 to provide each observation with a unique interal ID which allows to link to link other data entities to this observation and; 3 to have a clue to uniquely identify this observation in the field or to clean the dataset when combined with datasets from other sources.
Additional standardization resources
Datastructure Required data attributes are indicated by grey shaded fields in the table below.
- By clicking on the blue table title -> all data attributes become visible,
- By clicking on the data entity buttons -> all data ttributes become visible of that data entity,
- By clicking on the {} symbols -> the JSON becomes visible.